Benchmarking performance
Givanna Putri
2024-06-14
Last updated: 2024-06-14
Checks: 6 1
Knit directory: NextClone-analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown is untracked by Git. To know which version of the R
Markdown file created these results, you’ll want to first commit it to
the Git repo. If you’re still working on the analysis, you can ignore
this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20231011) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version d3d9673. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/.DS_Store
Ignored: data/cellranger_out/
Ignored: data/nextclone_out/.DS_Store
Untracked files:
Untracked: analysis/benchmarking_duration.Rmd
Untracked: data/benchmark_duration.csv
Unstaged changes:
Modified: analysis/DNAseq_data_analysis.Rmd
Modified: analysis/index.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
There are no past versions. Publish this analysis with
wflow_publish() to start tracking its development.
Introduction
To address reviewer’s comments demanding runtime benchmarking.
What was done? Run NextClone on both DNAseq and scRNAseq data setting chunks 10-50 at increment of 10. Duration was measured by checking the performance report generated by Nextflow. This duration was then manually copied from the html performance report file to the csv file read in as an input for this analysis.
The following shell script was run to generate the data:
# for scRNAseq
#!/bin/bash
module load nextflow
basedir=/vast/projects/Goel_senescence/nextclone_dev/07_analysis/pilot_dataset/02_run_nextclone
for nchunks in {10..50..10}
do
outdir=$basedir/output_20240613/nchunk_$nchunks
nextflow run main.nf \
--mode scRNAseq \
--scrnaseq_bam_files $basedir/for_bioinf_first_submission/data/scrnaseq_bam_files \
--n_chunks $nchunks \
--publish_dir $outdir \
-with-report $outdir/report_sc_nchunk"$nchunks".html
done
# for DNAseq
#!/bin/bash
module load nextflow
basedir=/vast/projects/Goel_senescence/nextclone_dev/07_analysis/ngs_v1/run_nextclone/for_bioinf_rebuttal/
datasets=('8k' '10k')
for dat in "${datasets[@]}"
do
for nchunks in {10..50..10}
do
outdir=$basedir/output_20240321/$dat/nchunk_$nchunks
# only need to run this once. ran it for testing the loop is ok.
# echo "Creating $outdir"
# mkdir -p $outdir
nextflow run main.nf \
--mode DNAseq \
--dnaseq_fastq_files $basedir/data/dnaseq_fastq_files/$dat \
--n_chunks $nchunks \
--publish_dir $outdir \
-with-report $outdir/performance_report
done
donelibrary(data.table)
library(ggplot2)
library(scales)
library(stringr)Analysis
duration_dt <- fread("data/benchmark_duration.csv")Have to convert the duration containing number of hours, minutes, seconds to just minutes.
duration_dt$duration_in_hours <- sapply(duration_dt$duration, function(dur) {
dur_split <- str_split_1(dur, " ")
hour <- as.numeric(gsub("h", "", dur_split[1]))
minute <- as.numeric(gsub("m", "", dur_split[2]))
second <- as.numeric(gsub("s", "", dur_split[3]))
total_duration_in_hour <- hour + (minute / 60) + (second / 3600)
return(total_duration_in_hour)
})Descramble the dataset column so we can find what dataset and number of chunk
duration_dt$nchunk <- sapply(duration_dt$dataset, function(dat) {
dat_split <- str_split_1(dat, "_")
for (component in dat_split) {
if (length(grep("nchunk", component)) > 0) {
nchunk <- as.numeric(gsub("nchunk", "", component))
return(nchunk)
}
}
})
duration_dt$nchunk <- factor(duration_dt$nchunk, levels = seq(10, 50, 10))
duration_dt$dataset_name <- sapply(duration_dt$dataset, function(dat) {
dat_split <- str_split_1(dat, "_")
for (component in dat_split) {
if (component == "sc") {
return("scRNAseq")
} else if (component == "8k") {
return("DNA-seq (dataset A)")
} else if (component == "10k") {
return("DNA-seq (dataset B)")
}
}
})Plot duration versus chunk as line graph
ggplot(duration_dt, aes(x = nchunk, y = duration_in_hours, colour = dataset_name, group = dataset_name)) +
geom_line(linewidth = 0.5) +
geom_point(size = 2) +
scale_y_continuous(breaks = pretty_breaks(n=10)) +
theme_classic() +
labs(x = "Number of FASTA files", y = "Duration (hours)", colour = "Dataset",
title = "Benchmarking of NextClone Runtime") 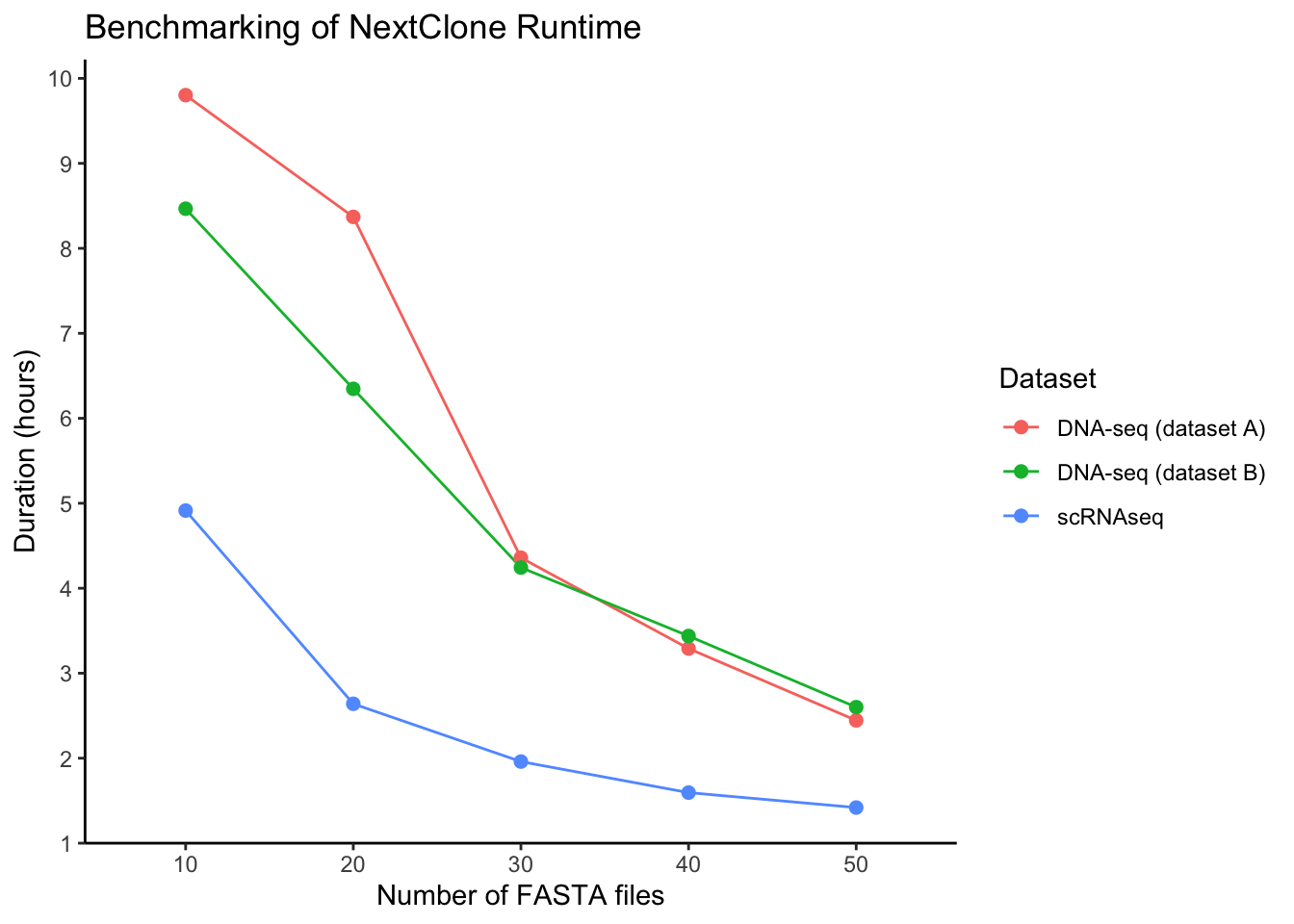
sessionInfo()R version 4.4.0 (2024-04-24)
Platform: x86_64-apple-darwin20
Running under: macOS Sonoma 14.0
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Melbourne
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] stringr_1.5.1 scales_1.3.0 ggplot2_3.5.1 data.table_1.15.4
[5] workflowr_1.7.1
loaded via a namespace (and not attached):
[1] gtable_0.3.5 jsonlite_1.8.8 highr_0.10 dplyr_1.1.4
[5] compiler_4.4.0 promises_1.3.0 tidyselect_1.2.1 Rcpp_1.0.12
[9] git2r_0.33.0 callr_3.7.6 later_1.3.2 jquerylib_0.1.4
[13] yaml_2.3.8 fastmap_1.2.0 R6_2.5.1 generics_0.1.3
[17] knitr_1.46 tibble_3.2.1 munsell_0.5.1 rprojroot_2.0.4
[21] bslib_0.7.0 pillar_1.9.0 rlang_1.1.3 utf8_1.2.4
[25] cachem_1.1.0 stringi_1.8.4 httpuv_1.6.15 xfun_0.44
[29] getPass_0.2-4 fs_1.6.4 sass_0.4.9 cli_3.6.2
[33] withr_3.0.0 magrittr_2.0.3 ps_1.7.6 grid_4.4.0
[37] digest_0.6.35 processx_3.8.4 rstudioapi_0.16.0 lifecycle_1.0.4
[41] vctrs_0.6.5 evaluate_0.23 glue_1.7.0 farver_2.1.2
[45] whisker_0.4.1 colorspace_2.1-0 fansi_1.0.6 rmarkdown_2.27
[49] httr_1.4.7 tools_4.4.0 pkgconfig_2.0.3 htmltools_0.5.8.1